Частотный словарь полутора гигабайт русских текстов
Сентябрь 2002
У меня давно было желание провести статистическое исследование
достаточно представительной выборки русских слов, чтобы найти
среди них самые часто употребимые, самые длинные, самые средние...
в общем, все самые-самые.
И вот, когда у меня в руках оказался диск «Библиотека в кармане»
(выпуск 4), я понял, что моя мечта близка к осуществлению.
Написание программы заняло совсем немного времени, и теперь я
с удовольствием представляю вам результаты этого эксперимента.
Основные результаты
Было просканировано около 1,5Гб (более полумиллиона печатных
страниц) русских текстов различной тематики:
классика, детективы, фантастика, специальная литература,
словари и энциклопедии. Общая длина всех текстов составила более
двухсот миллионов слов. (Точнее, словоформ. Здесь и далее
речь будет идти только о словоформах.)
Среди этих двухсот миллионов уникальными оказались всего лишь
чуть более двух миллионов словоформ, причём 47% из них
встретились только один раз. (Любители точных цифр найдут их
в результатах одного из прогонов ниже.)
Наиболее часто употребимыми оказались, как и следовало ожидать,
служебные слова – союзы, предлоги, частицы и местоимения.
А именно (первые два десятка):
и, в, не, на, что, я, с, он, а, как, но, его, к, это,
все, по, из, у, она, за, от...
См. также: 300 наиболее часто употребимых словоформ.
Интересно отметить высокую частотность однобуквенных сокращений:
- п – пункт, тому подобное;
- г – господин, грамм, город;
- м – метр, мадам, месье, мост и т.п.
Однако, наиболее часто «одинокие» буквы встречаются как инициалы.
Статистика корпуса текстов
Вот статистика одного из прогонов. Точнее было бы назвать эти
числа статистикой диска «Библиотека в кармане», так как от одного прогона
к другому меняется только время, остальные числа остаются те же.
(Правда, я добавил к этому диску несколько своих файлов, что
в общем-то, неважно.) Итак:
Всего просканировано:
- Байт: 1.513.487.254
- Файлов: 3.676
- Словоформ: 205.448.447
- Из них уникальных: 2.133.715
Динамика роста размера словаря
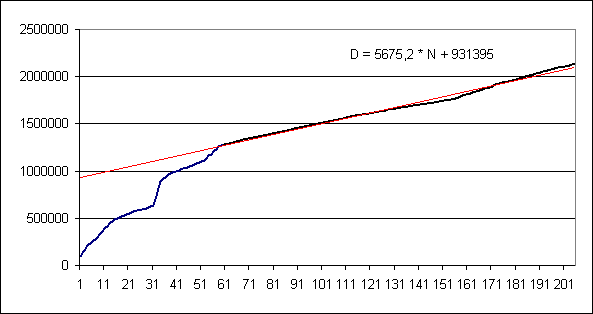
На следующем графике показана динамика роста размера словаря.
В качестве единицы «времени» (горизонтальной оси) выбран миллион слов
входного текста. По вертикальной оси отложен размер словаря в словах.
Те же самые данные, представленные в виде приращения числа незнакомых слов
на каждый миллион слов входного текста (производная первого графика):
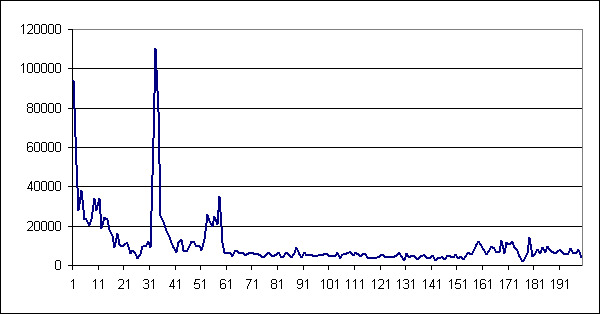
Как видно, после примерно 60 млн. слов устанавливается относительно ровное
приращение в несколько тысяч слов на миллион, продолжающееся до конца графика.
Ярковыраженный всплеск в области 32 млн. соответствует периоду прохождения словарей
(из которых самые большие – Даля и Мюллера).
Проведя линейную аппроксимацию по области за 60 млн. слов,
получаем показанную на первом графике формулу для оценки размера
словаря в зависимости от объёма проиндексированных текстов.
Полученное число необходимо умножить на средний размер одной словарной статьи.
Он может быть оценен как средняя длина слова + размер служебной информации,
зависящий от формата хранения данных.
Средняя длина слова по результатам измерений на материале диска «Библиотека в кармане»
составила 5.36282 буквы. При этом не учитывались слова длиной более 40 букв.
Детали реализации на C++
Следующая информация будет более интересна программистам, нежели
лингвистам.
На доработку и оптимизацию этой программы, на «доведение её до ума»
ушло около двух месяцев и, признаться, я очень доволен полученным
результатом. У программы большой потенциал: она может быть развита
в реальную систему индексации текстов, ничуть не уступающую
уже имеющимся в производительности.
Вот краткое описание функциональности программы и её возможностей.
Программа просматривает указанный каталог, его подкаталоги и
архивы RAR в поисках текстовых файлов (*.txt). Все найденные
файлы пословно анализируются, составляется словарь уникальных
словоформ со счётчиками появлений в тексте каждой словоформы.
Программа «понимает» две кодировки русского текста,
DOS-866 и Windows-1251. Пока программа безразлична к морфологии,
формально «кодировкой» считается и латиница, так что для выбора
кодировки предусмотрены три ключа (-dos, -win
и -lat).
Конечно же, число поддерживаемых кодировок может быть легко расширено.
Несколько замечаний по сути проведённых оптимизаций.
- Выбрана оптимальная структура словаря, исходя из требований
быстрого поиска и вставки. Кандидатов, по сути, не так уж много,
а именно std::map (двоичное дерево) и
hash_map (список с хэш-таблицей).
Класс hash_map пока не является частью
стандартной библиотеки C++, но присутствует во многих её
реализациях. В частности, я пытался применить
hash_map из Visual C++ .Net и SGI STL
(www.sgi.com/Technology/STL).
SGI STL мне так и не удалось заставить работать с VC.
К тому же, моя собственная реализация hash_map
для данного приложения оказалась гораздо более эффективной (более чем в 2 раза),
чем та, что поставляется с VC7, поэтому я остановил свой выбор на ней.
- Использование строк фиксированного размера (класс
FixedString <size_t>) для представления слов
в словаре позволило существенно снизить требования к памяти.
Если недостатка свободной оперативной памяти нет, то с точки зрения
производительности предпочтительнее
использование std::string.
Программа имеет ключи для выбора структуры словаря (map или hash_map) и представления слов в нем (string или FixedString),
что позволяет варьировать производительность програмы и её требования
к памяти на этапе выполнения.
- Вызов streambuf::sbumpc () вместо обычного
istream::get () ещё немного повысил
производительность.
istream::get в VC реализована не очень эффективно.
Исходный текст программы может стать хорошим обучающим примером
для тех, кто изучает программирование на C++ (не для новичков).
Вы можете использовать приведённые здесь исходные коды в своих
проектах. Если такое произойдёт, я буду рад узнать о том, какое
применение нашли мои разработки. Любые отзывы и замечания
по программе будут также кстати.
Требования к программному и аппаратному обеспечению
Windows 95 и выше. Процессор класса Pentium.
Необходимый объём оперативной памяти зависит от объёма
анализируемых текстов. Для диска «Библиотека в кармане»
необходимо 128 мегабайт (умеренное использование файла подкачки),
рекомендуется 256М.
Время индексирования всего диска вместе с распаковкой архивов
на различных компьютерах:
| Компьютер | ОС | Время, средняя скорость |
|---|
| до оптимизации | после |
|---|
| PII-350/128 | W2K Pro | 52 мин, 65000 слов/с | |
| PII-350/196 | W2K Pro | 43 мин, 79000 слов/с | 21 мин, 163000 слов/с |
| PIII-750/256 | NT4 | 26 мин, 133000 слов/с | |
| PIII-1100/240 | XP | 24 мин, 135000 слов/с | 10 мин, 342000 слов/с |
Достижению такой высокой производительности во многом способствовало
использование хэшированного ассоциативного массива (см. hash_map.h)
для представления словаря.
Переносимость
Проверено на Visual C++ 6.0, Visual C++ .NET, Borland C++ 5.5.
В связи с неполной поддержкой исключений в VC6.0 некоторые
ошибки диагностируются как "Unknown error".
Этих проблем нет у VC.NET и BC5.5.
Модули dirrec.cpp (рекурсивный просмотр подкаталогов)
и unrar.cpp (распаковка RAR-архивов) используют WINAPI,
поэтому потребуют переписывания при их переносе на не-Windows
платформу.
Скачать
Вот и собственно программа:
statsbin.zip (195K) –
исполняемые файлы (stats.exe и unrar.dll)
statssrc.zip (15K) –
исходный код на C++
Ссылки